Backing up Google Photos
Do you want to back up your Google Photos outside Google, and keep them backed up continuously, in full original quality, while minimising disk space? Here's how I do it.
I ended up with many photos only stored in Google Photos. Worryingly, these photos weren't backed up outside of Google.
I was really worried about how to set up backups; I'd heard a lot of people complain about how hard it is to get your photos out of Google Photos. I particularly heard many complaints about Takeout not exporting all the metadata; this is complicated; more on that below.
This put me off doing it for a long time. I read MANY blogposts & Reddit threads before choosing my strategy. It was a lot of faff, so I'm keen to write it up to save you the hassle.
My Strategy TL;DR
- I schedule a Google Takeout of my entire Photos library for every two months, using the largest (50 GB) archive size.
- I manually click download the archives to an external drive.
- I extract the archives with a script.
- I back up and deduplicate the photos and metadata with 'restic' backup software, but you could use any deduplicating backup software.
Problems to solve
These are my tradeoffs; yours may be different.
- Image Quality: I want it best available quality please.
- Metadata: Many people complain that the Google Photos API doesn't include metadata like date or GPS. I want this backed up, though I don't need it stored in the photo's EXIF information: this is a backup for emergencies, not a migration to another tool.
- Low-overhead: I want to automate where possible. I don't want my technique to break when Google changes their Takeout format.
- Deduplication: Storage is expensive. I want to deduplicate data. I don't want two backups to take up 2x the data.
- Retention: I eventually want to 'age out' old backups and not pay for their data forever.
Where to get the photos from
This is why it's so hard to figure out. You have many options for getting your photos out:
Google Takeout is the natural option. Takeout exports all the photos in their original quality chosen when uploaded (e.g. if you chose full quality, you get the original bytes with EXIF, if you chose space saver, you get recompressed photos and most of the EXIF data stripped).
The original uploaded EXIF data where it was present when uploaded at full quality, and includes date and GPS data in sidecar JSON files alongside the images.
Google Photos API might be expected to be a good place to go, and would running (say) nightly continuous backups. But the API doesn't return the original quality images with original EXIF metadata, and the API doesn't expose GPS location.
Aside: The API's EXIF stripping is frustrating but understandable: the EXIF information contains GPS, I'm not sure it's a good idea to expose that to any website that can convince the user to click 'accept' on an OAuth prompt.
I discounted options that just use the Google Photos API: RClone, Photo Vault One, SyncBackPro, gphotos-sync, Quiver Photos, because I want full quality exports.
The Google Photos Web App offers a download option: either photo-by-photo, or selecting an album and downloading as a .zip. The google-photos-backup tool scripts this with a headless browser API. It's a neat hack, enabling continuous backups, but I wasn't comfortable handing over my credentials to it.
Google Drive used to have an integration with Google Photos that exposed your photos as files, making it easy to back them up, but it was shut down. I imagine it's hard to maintain a filesystem API to Google Photos as the product evolves, and you can edit photos and metadata in Google Photos. I've still got a "Google Photos" folder in Google Drive, but it doesn't sync to Google Photos any more; I haven't figured out what to do with it yet.
Some tools use a Combination: API + Takeout. e.g. Timeliner merges data from Takeout and the Google Photos API, to get full GPS information from Takeout and merge that with continuous backups from the API. You can see why, but gosh, what an unfortunate situation.
I chose Google Takeout, as it has the original uploaded quality, and the full GPS metadata in sidecar .json files. I can live with waiting two months between backups.
Takeout Options
Google Takeout gives you choices to make. Here's mine:
Transfer to: Send download link via email.
Frequency: Export every 2 months for 1 year. I want this to be continuous.
Albums to export: all of them. This is a backup, I want it all. Some people just download the "Photos from <year>" albums, but I'm worried that might not download everything. Give me everything; I will deduplicate later.
File type: .zip. I think I heard one of these formats had a more precise timestamp format? Whatever, the timestamp is in the JSON sidecar anyway.
File size: 50 GB. Choose the largest you can, because you have to click each download link manually. The first time I did this, I chose 10 GB, and had to manually download 37 files.
Download your Takeout before the files expire in 7 days! The first time I did this, I missed downloading one file, and it expired, and I had to start over! I almost cried.
Takeout Larger Than Expected
Despite Google Photos saying "174.5 GB used", my Takeout download was surprisingly 7 x 50GB = 350GB. What gives?
- Photos in albums show up in Takeout under a folder for the album name, and a folder for the year.
- Some photos "don't count for storage" – either they were uploaded with "Storage Saver" mode, or perhaps there was a discontinued promotion where Pixel phones got free storage.
After deduplication, my photos take up 289GB. So I guess I have a lot of photos where Google isn't charging me for storage?
This was a sad surprise: my laptop didn't have enough free space to store all these photos!
Instead, I used a spare 512GB SD card as the space to do this backup. It's not fast, but it's faster than my internet connection. I'm sensitive about storing photos unencrypted – when I bought this SD card second hand, it still had the photos of the previous owner on it – so I formatted the card with an encrypted APFS partition first in macOS Disk Utility. Now no traces will remain, even after deleting the files.
Downloading Takeout Archives
Sadly, I don't know a way to automate downloading these archives. The URLs are auth'd, you have to click them in a real browser, you can't just copy them to cURL.
My steps:
- Open Chrome
- In Chrome Settings, change my default download folder to the external disk
- Click all the links
- Leave my computer awake till they finish
Took about a day.
Extracting
My 512GB drive is too small to contain both the 350GB archives and their extracted versions. Extracting takes a long time for each file; so I didn't want to manually extract one, delete one, extract one, delete one, it would have taken a lot of time.
So I scripted extracting and then deleting the archive with this fish script:
for f in *.zip
echo unzip $f
echo rm $f
end
If you use bash, you have to write your own loop, sorry.
Remove the echo once you have verified the commands look reasonable. Again, leave the laptop on for a while.
Weird Stuff in the Takeout Archive
Errors: I got 'missing files' every time I took a takeout. I'm ignoring this; I guess if I'm requesting tens of thousands of photos, sometimes there will be transient errors. I hope the photo will be in the next archive.
Untitled(270): I had over 200 Untitled folders. A lot of these are anonymous share albums. I don't think these numbered folders are stable between takeouts, making it hard to just 'extract over the top of the last archive'.
Failed Videos: This folder contains videos that Google Photos couldn't transcoded. These all seemed to be sub-second videos or corrupted videos. You can see them (and delete them) in Google Photos Web UI: Settings, Unsupported videos, View. Or go to https://photos.google.com/unsupportedvideos. I deleted all of these.
Deduplication
I have the same photos duplicated in the "Photos from 2024" folder and named album folders. I don't want to pay for double storage.
There's many ways to solve this problem:
Timeliner stores the Google Photos in sqlite database and deduplicates images. It looks very smart, and was recommended, but is deprecated, and the new version is a "not ready yet" early-stage startup. Doesn't feel like a stable foundation to build backups on yet.
jdupes and rdfind look for duplicates and turn them into hardlinks or symlinks. But hard-link deduplication isn't preserved when backing up to other computers / cloud storage.
Git is a content-addressable filesystem, implicitly deduping things. But Git has a repuation of not working well with large files.
Git Large File Storage replaces large files in Git with pointers, but then I still have to store the pointed-to data somewhere.
Perkeep (aka Camlistore) is content-addressable storage too aimed at preserving your digital life forever. Sounds perfect?
I tried Perkeep, I found it's datamodel a bit hard to understand – e.g. File Nodes or Permanodes? 5GB of photos were stored on disk as 10GB because of a caching bug. I respect Perkeep as an innovator in this area, but it seems stalled: the last release was in 2020.
Deduping Backup Software: Most modern backup software uses content-addressable-storage, which automatically dedupes. I have previously blogged about Cloud Backup Software.
Conclusion: I think using a normal, deduping, snapshotting backup software is a good idea! Good backup software:
- Solves deduplication.
- Gives you snapshots you can set retention policies on (so you aren't paying for old backups forever).
- Encrypts the data.
- Works with offsite storage, including cloud storage.
- Is automatically robust to new Google Takeout data format changes (i.e. there's no parsing of the JSON, it's all just dumb files).
Backup Software
You could use whatever backup software you want. Backblaze is a common commercial answer.
I usually use Arq to backup data from my laptop, but as I don't have room on my laptop disk for all these photos, I thought I'd try something different.
I tried Restic backup. Restic is open-source, written in Go (so it probably handles errors), dedupes data, is seeing very active development (last release two weeks ago), has a large ecosystem, and can backup to nearly any storage service via RClone.
I followed Restic's docs to prepare a new backup repository and run a backup:
$ restic -r sftp:mark-restic@nas:/home init
$ restic -r sftp:mark-restic@nas:/home --verbose --read-concurrency 8 backup Takeout/
I created a Restic repo over SFTP on my NAS, and backed up the Takeout/ folder.
Restic's deduplication was effective: I took two backup snapshots a few days apart, and the size of the restic repo barely grew.
Every two months, I rerun the last command, and restic deduplicates all the new data against the old data.
If I could get a good GUI for Restic, maybe I'd consider using it for my laptop backup too.
Metadata: Google Photos' Data Model
Photo files often (but not always) have EXIF data inside containing timestamps and GPS location.
I'll go over some of Photos' data model, because I think it makes clearer the tradeoffs around EXIF data.
Google Photos stores photos and videos (I'll refer to both as just "Photos").
Photos are uploaded from devices to Google Photos, and stored with some Quality:
- Original Quality: same resolution.
- Storage Saver (originally "High Quality"): slightly reduced quality. Resized to <16MP or 1080p.
- Express Quality: resized to <3MP or 480p.
I believe that for Original Quality, the downloaded file is the same, including all EXIF information, as when originally uploaded. For Storage Saver & Express Quality, that may not be true.
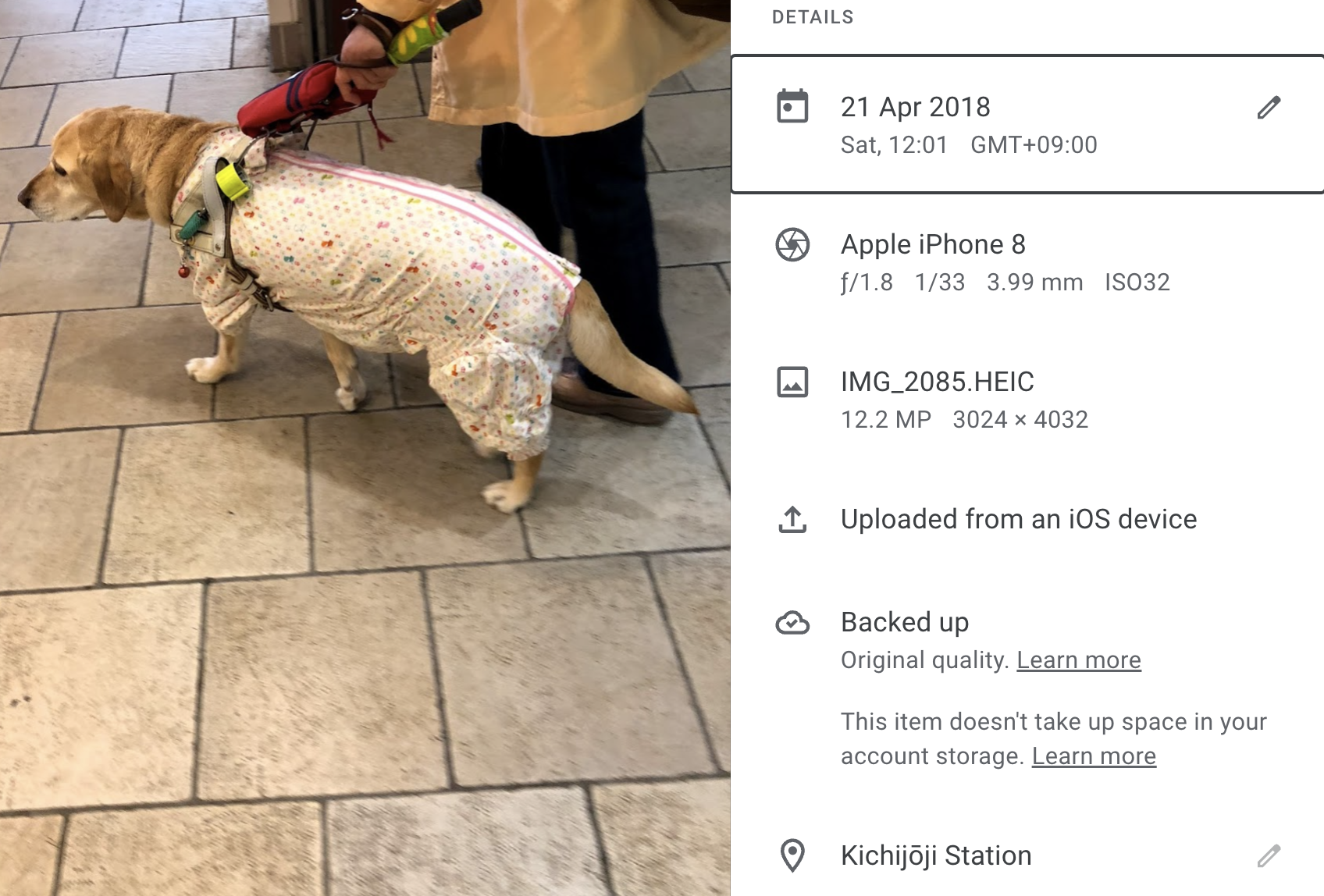
Date: Google Photos parses the date from the EXIF when uploaded.
If there's no EXIF data, some sometimes the time of the upload or the timestamp on the file. You can also edit the photo's date post-upload. In these situations, the date is not "inside" the file's bytes, and the new date will not be present as an EXIF tag when you re-download the photo.
But Google Takeout will include the date in a JSON sidecar.
GPS Location: Google Photos parses the location from the photo EXIF.
Like date, you can also edit the GPS location in Google Photos post-upload. In this situation, the new GPS location is also not inside the file's EXIF.
Date and Location are inferred and editable. Google Photos doesn't overwrite the original information in the photo, but rather chooses to put this information in a "json sidecar" file alongside the image, instead of re-encoding information into EXIF.
$ cat Takeout/Google Photos/Photos from 2018/IMG_2085.HEIC.json
{
"title": "IMG_2085.HEIC",
"description": "",
"imageViews": "6",
"creationTime": {
"timestamp": "1524354063",
"formatted": "21 Apr 2018, 23:41:03 UTC"
},
"photoTakenTime": {
"timestamp": "1524279700",
"formatted": "21 Apr 2018, 03:01:40 UTC"
},
"geoData": {
"latitude": 35.7035,
"longitude": 139.57989999999998,
"altitude": 67.02,
"latitudeSpan": 0.0,
"longitudeSpan": 0.0
},
"geoDataExif": {
"latitude": 35.7035,
"longitude": 139.57989999999998,
"altitude": 67.02,
"latitudeSpan": 0.0,
"longitudeSpan": 0.0
},
"url": "https://photos.google.com/photo/AF1QipM23VLBvQ2A9UqFSIwFz40VTsCCxAcd1gk8akyj",
"googlePhotosOrigin": {
"mobileUpload": {
"deviceType": "IOS_PHONE"
}
}
}The JSON sidecar for my photo of a dog above. It includes date, location.
I think putting the data into JSON sidecars is a reasonable conservative tradeoff: EXIF is very complicated (e.g. there are many ways to specify a timestamp), overwriting EXIF would potentially lose data.
Do you lose Metadata exporting in Takeout?
There are a lot of complaints about this.
Some metadata may be removed from files when uploading not at "Original Quality"; but you find the most-important metadata in the JSON sidecar.
If Google Photos edits or infers the GPS or Date, that information isn't overwritten in the EXIF, but it is in the JSON sidecar.
So: I think I'm happy with the output. All the data I see in the Google Photos UI is in Takeout.
Metadata Repair Tools
If you're moving from Google Photos to another tool, it's natural to want to take these JSON sidecars and turn it into EXIF the other tool can understand.
This isn't straightforward: EXIF is pretty complicated. There are tools for this: GooglePhotosTakeoutHelper is recommended universally. Metadata Fixer ($24) is not recommended. google-photos-takeout.sh and GooglePhotosExportOrganizer are discontinued. You could always roll your own script with exiftool.
Restoring The Backup
Everyone says: Backups are only as good as restores!
But I confess I haven't done a "full restore". Getting this back into Google Photos would be a huge undertaking, and I can't be bothered.
I reckon it would be a disaster trying to reimport. I'd have to use Google Drive's Photo uploader, and the timestamps would all be wrong, unless I fix them first. I'd probably cry. I'd have to use a Metadata Repair tool above.
I've got peace of mind from having the photo & JSON files saved, and that's all I want.
Wishlist / Future
I'll watch Timelinize to see if they can solve online Photos backup commercially.
I'm hoping that Google will make this easier, somehow – maybe by adding an option to overwrite EXIF data on export, or setting modified-time on the archive from the metadata?
Maybe we could make a standard format for photo libraries.
I wish we had better archive formats that automatically dedupe files across folders; tar and zip don't.
Is there an easier way?
Please let me know! It's still a huge pain to do this.



Comments ()